当我们说消息队列消费时,指的是什么?
几年前的我其实一直没太理解到底所谓的流处理和我们普通的消息队列的处理有什么区别。那时还没有可以给你任何你想要的知识的大模型,从一些文章里得到的最直观最简单的结论就是:流是连续的。
那我们的消息队列的处理也是无限的啊,除非业务调整或者公司关门了,肯定不会说消息队列突然没了,对吧?所以这很显然不是问题的答案。而当时涉及到新项目上马和技术选型,在众多的消息处理和流处理框架中,选择了Flink。
刚开始的业务逻辑还没那么复杂,所以虽然遇到了一些问题,但也都陆续解决了。随着业务越来越重,消费能力不足的问题逐渐暴露出来,消费能力变得很脆弱,一点小小的抖动马上就会引起Kafka topic的堆积报警,而真正的问题远不止于此。
使用流处理框架来做消息处理的问题
流处理的过程通常不涉及外部服务的依赖,是作业内部的CPU运算,比如把数据分组、变换、求和等等,一个具体的场景可能是收集到传感器采集的数据,然后算每10秒的平均值,再计算平均数的增长率。这样的过程其实就完全依赖于作业运行的集群本身的算力,如果消息量大了,就看哪一步的计算是瓶颈,增加算子就可以了,基本上不会出现某个TaskManager上的某个节点卡住,导致作业整体背压的情况。
但消息处理通常要处理的是更复杂的业务,具体来说就是可能需要调接口、写数据库、和各种各样的系统做交互,比如上游传来的消息是一个比较精简的版本(可能受限与最上游消息队列的长度限制),然后在处理过程中需要补充更多的详情,再进行一些判断如此这般,而依赖的这些接口性能又不完全相同,稳定性保证也不完全相同,这时候作业的消费能力或者稳定性就完全取决于这些外部服务的稳定性了。
那你会说,这么说所有的系统不都是这样的吗?只要和外部系统交互,这个问题就一定存在。是,也不完全是。
Flink的杀手锏同时也是软肋
Flink的杀手锏就是检查点机制,它会周期性地向数据流中插入Barrier,当每个算子接收到所有输入流中的Barrier时,会执行快照操作,保存当前状态,当作业中的所有算子全部都完成保存状态的操作,或者说检查点完成时,才继续下一轮操作。这样做的实现了分布式快照,确保了整个系统状态的一致性,还能支持故障恢复,当系统发生故障时,可以从最近的一致性检查点恢复。看起来是没什么问题,但实际上问题很大。
最常见的问题就是某个算子中调用的某个服务偶发变慢了,这时候这个算子的处理能力就会变慢,也许这个算子只是消费的一个Topic中40个分区中的1个,但这个算子由于处理速度变慢就会更晚接收到Barrier,也就更晚地保存状态,那么其他的正常的算子呢?它们早就接收到了Barrier,保存了状态——然后等着这个最慢的算子也完成。虽然其他的算子没有问题,但由于要做一个全局的一致性检查点,其他的39个分区也会开始堆积。
那你说堆积就堆积吧,等它自己恢复了不就好了吗?
堆积发生时,上游仍然在生产数据,所以堆积的消息会快速增加。好了,终于等到前面那个慢的算子完成了状态提交并且在超时之前完成了检查点(算你运气好),这时候Kafka里和Flink的Source算子里都已经堆积了大量的数据,你幻想它会以最大速度开始消费?No No No,首先,它的消费能力依赖于整个链路上最慢的一环,这时候整个系统的压力可能已经达到了平时了数倍,你依赖的那些服务有那么多冗余吗?它们能承受这种突然增加数倍的请求吗?不能,那它就变慢给你看。
结果就是,消息越堆越多,越多越慢。
而Flink标榜的自带的内部队列、天然反压机制在这时并没有发挥作用。
逐渐地我开始意识到了流处理和消息队列的真正区别。
Flink的原生流处理和SparkStreaming的microbatch的区别
我们依赖的接口多数是支持批量调用的,也就是拿多个id去请求一个接口,这样比用多个id分别去发起请求调用要更高效,但Flink并不原生支持这种行为,需要自己做内部计数器实现,这就还要自己维护状态了。但它所谓的原生流处理支持,其实说的是有时间窗口和计数窗口,这也对应了我前面的说它更适合用于统计某个窗口内的数据并计算窗口之间的数据变化,其实就是聚合操作,但这种状态的维护其实还是很重量级的,尤其对于需要调用外部接口的业务而言,因为你本身是并不需要去计算这个所谓“窗口”内的数据的关系的,只是需要把他们放在一起处理而已。
而SparkStreaming是通过小批量来模拟流的操作,这种小批量可以通过控制每隔多长时间触发一次计算或者每多少条数据触发一次计算来实现,所以某种程度上说其实更适合我们的场景。
消息处理的瓶颈在哪里?
消费消息队列的瓶颈在于依赖的业务接口或方法,而不在于消费消息队列本身。
所以当我们说要扩容时,其实扩的就是依赖的业务接口。那么我们就做好给这个瓶颈扩容就好了。但现实肯定没有这么简单,有以下这些限制。
消息队列本身的设计限制
Kafka这类基于数据分区的队列,消费者的数量不能大于分区数,不然不光不能增加消费能力,反倒会因为频繁的rebalance而让消费能力下降,而你又不能无限制地提高分区数,何况Kafka临时扩分区数量还是有风险的。
语言的限制
像PHP这类单线程的语言,只能一个进程消费一个Kafka分区,而一个进程内的消费能力非常有限,无论如何也只能用一个核心,所以根本不可能承载比较大的数据量。
业务场景的限制
说到底还是业务代码的处理能力太差了,尤其现在一些GPU处理图片甚至视频的场景,消息本身不多,但挡不住处理得慢啊,即便代码是Java,即便是多线程,但在这时都不顶用,慢就是慢。而你不可能因为消费能力差就去买更多的卡吧。。。。
说了半天怎么解决呢?
这是我设想的一个架构图。
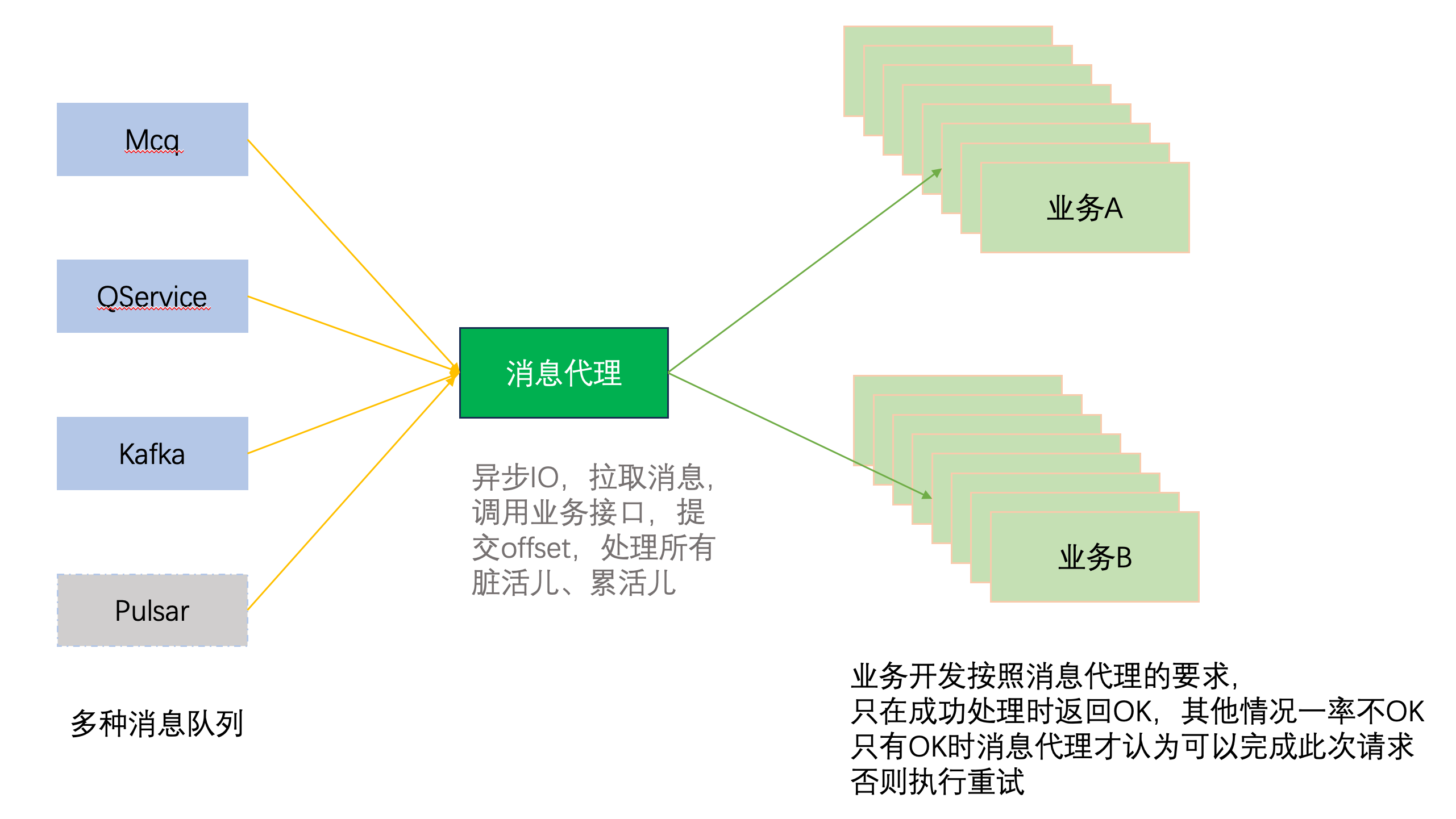
这个架构主要是2部分
- 中间的消息代理层,负责接入各种消息队列。比如针对Kafka、Pulsar这种支持offset提交的消息队列,就通过手动维护offset来保证数据的完整性,而其他不只支持offset的,则通过维护本地文件缓存或其他方式来实现,反正就是千方百计地保证数据完整性。
- 协议。协议规定的是和后端业务直接的交互,比如约定只有业务正确处理了这批/条消息才返回OK,其他情况都认为是失败,这样消息代理只有收到OK时才提交offset/删除本地缓存,否则将重放这批消息。
这样的好处在于将不是瓶颈的消息拉取部分单独解耦出来,让业务开发的同事专注于业务逻辑开发,而不用关心队列消费这些事情。同时,得益于K8s这类基础设施,作为HTTP服务提供的Pod可以用Deployment的方式快速水平扩容,而由于中间层的存在,就不用受限于诸如分区数、进程/线程数这些,实现了足够的弹性。
中间这块的逻辑计划用Golang实现,因为主要是IO的处理,数据的拉取和调用HTTP接口,可以重复利用Golang容易并发、异步IO、云原生的优势,快速启动、快速扩容,非常适合做这类中间件。